Abstract
Humanoid behavior foundation models aim to acquire reusable whole-body control policies from broad human motion priors, enabling a single controller to produce diverse and expressive behaviors. However, existing motion-centric foundation policies largely assume that the reference motion is already physically compatible with the robot's surroundings. This assumption breaks when the demonstrator, operator, and robot inhabit different environments: a human motion may specify the intended behavior, but not the footholds, clearance, body height, or contact timing required by the robot's local terrain.
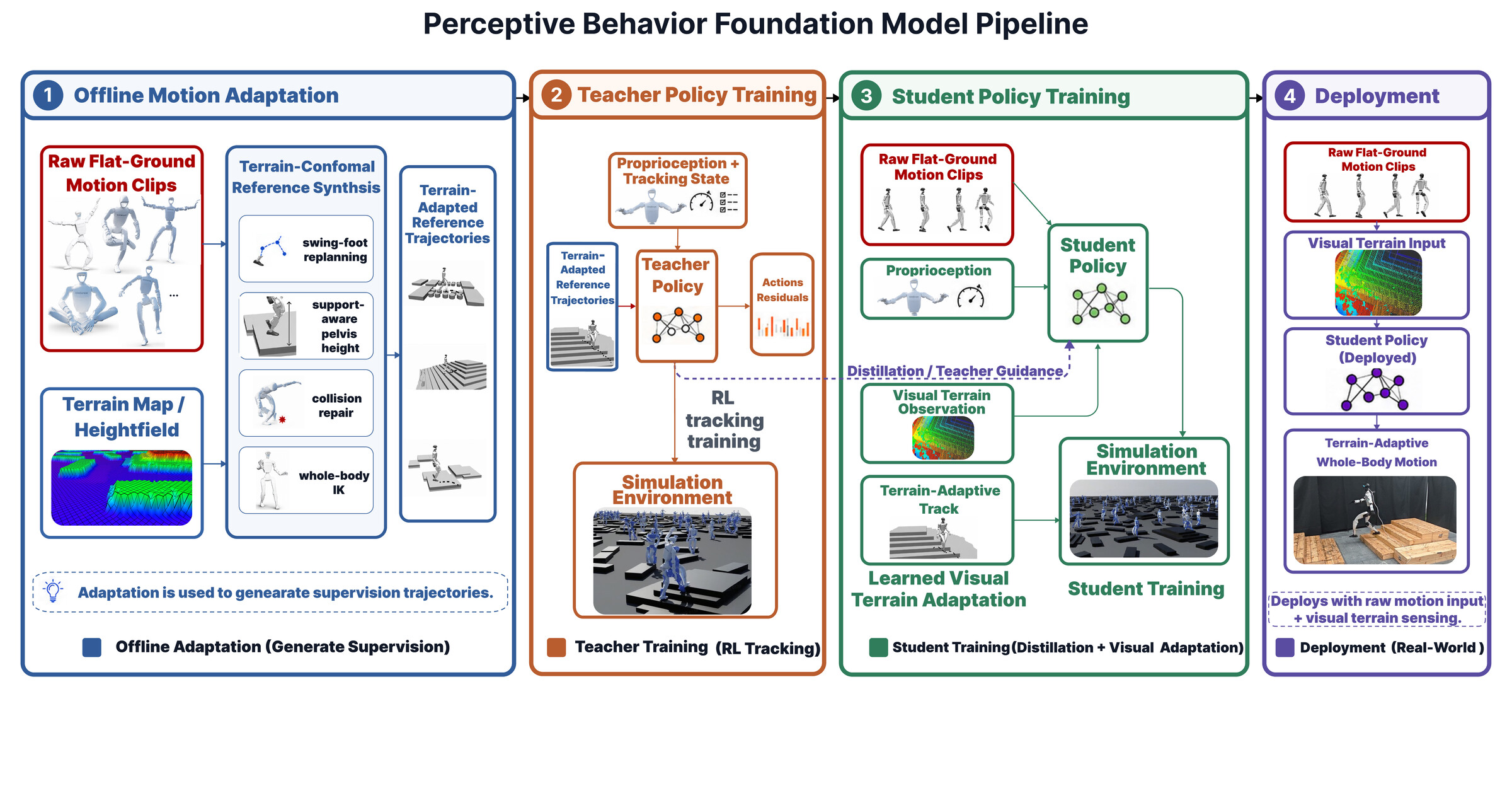
We introduce Perceptive Behavior Foundation Model (Perceptive BFM), a terrain-aware humanoid control framework that grounds human motion priors in robot-centric perception. The model preserves raw kinematic motion references as the behavioral interface, while using local terrain observations to adapt contacts, posture, and timing.
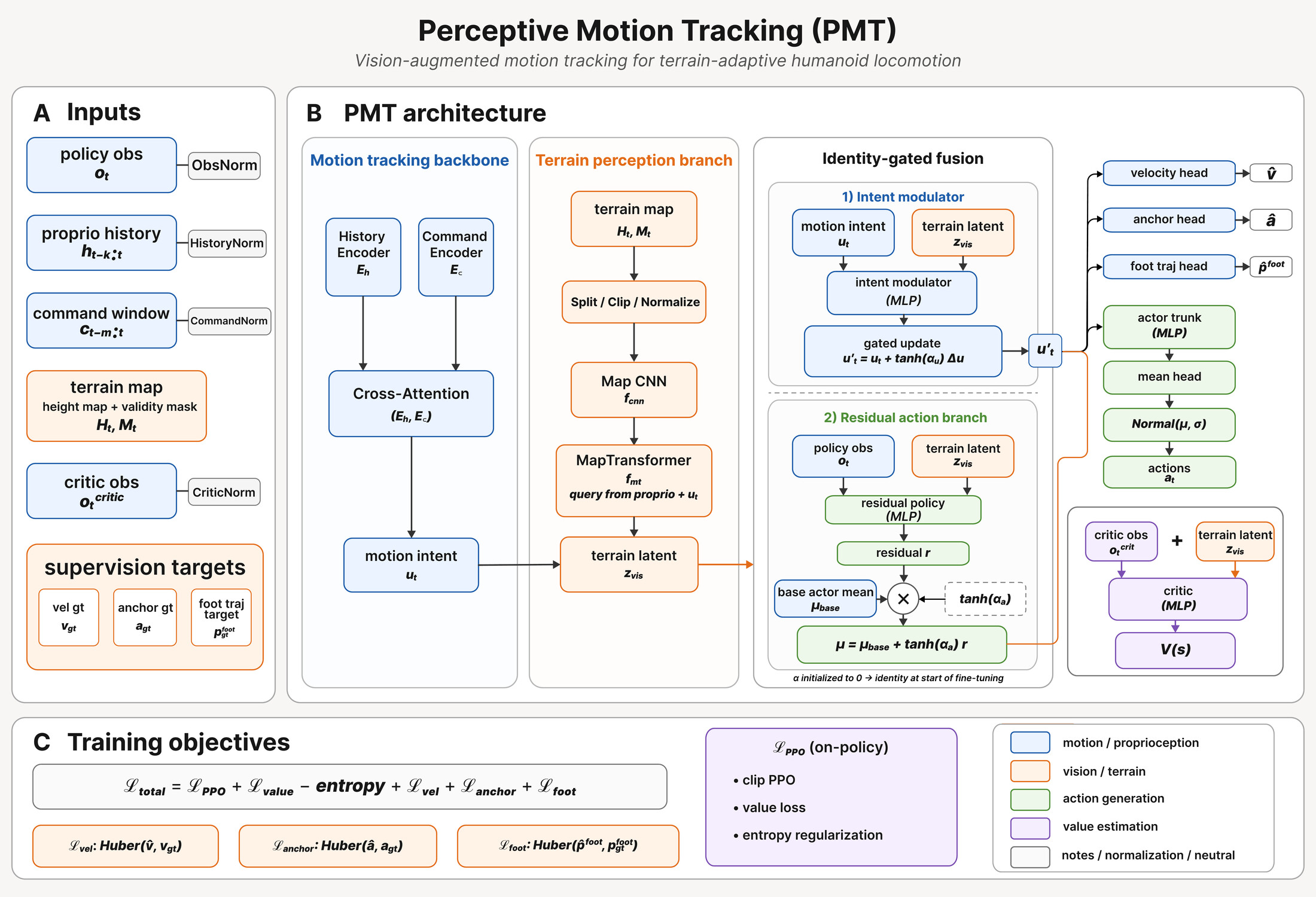
To provide scalable terrain supervision, we develop terrain-conformal reference synthesis (TCRS), which converts locomotion-oriented human motion clips into terrain-consistent references through contact-aware foothold construction, foot-geometry-aware swing optimization, support-aware root reconstruction, collision repair, and multi-point inverse kinematics. We then train a blind adapted-reference teacher and transfer its terrain-conformal behavior to a deployed raw-reference student through target-frame action alignment. The student is implemented as an identity-gated Transformer tracker, where terrain features enter through residual pathways initialized to preserve the motion-tracking prior and trained to produce local corrections only when needed.
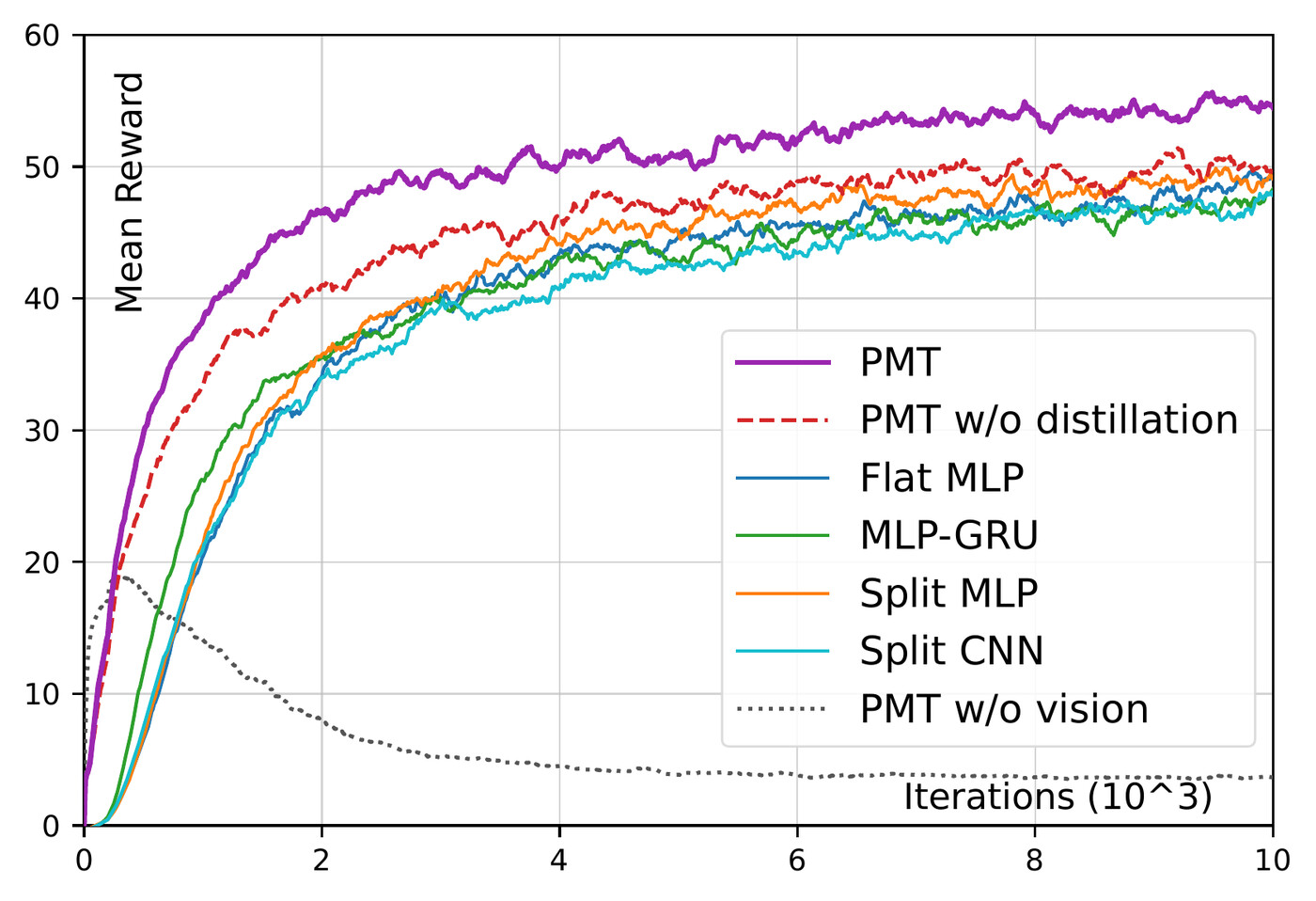
Across controlled simulation and qualitative real-robot rollouts, a single policy tracks a wide range of behaviors — locomotion, stylistic motions, acrobatic maneuvers, and motion-capture teleoperation — and is exercised on stairs, slopes, sparse supports, recessed obstacles, grass, and irregular indoor/outdoor terrain. The results indicate that robot-centric perception can transform human motion priors into terrain-compatible whole-body behavior without changing the raw motion command interface.